 Multiple Exceptions (user mode) - Modeling Example
Multiple Exceptions (user mode) - Modeling Example Multiple Exceptions (kernel mode)
Multiple Exceptions (kernel mode) Multiple Exceptions (managed space)
Multiple Exceptions (managed space)- Multiple Exceptions (stowed)
 Dynamic Memory Corruption (process heap)
Dynamic Memory Corruption (process heap) Dynamic Memory Corruption (kernel pool)
Dynamic Memory Corruption (kernel pool)- Dynamic Memory Corruption (managed heap)
 False Positive Dump
False Positive Dump Lateral Damage (general)
Lateral Damage (general)- Lateral Damage (CPU mode)
 Optimized Code (function parameter reuse)
Optimized Code (function parameter reuse) Invalid Pointer (general)
Invalid Pointer (general)- Invalid Pointer (objects)
 NULL Pointer (code)
NULL Pointer (code) NULL Pointer (data)
NULL Pointer (data) Inconsistent Dump
Inconsistent Dump Hidden Exception (user space)
Hidden Exception (user space)- Hidden Exception (kernel space)
- Hidden Exception (managed space)
 Deadlock (critical sections)
Deadlock (critical sections) Deadlock (executive resources)
Deadlock (executive resources) Deadlock (mixed objects, user space)
Deadlock (mixed objects, user space) Deadlock (LPC)
Deadlock (LPC) Deadlock (mixed objects, kernel space)
Deadlock (mixed objects, kernel space) Deadlock (self)
Deadlock (self)- Deadlock (managed space)
- Deadlock (.NET Finalizer)
 Changed Environment
Changed Environment Incorrect Stack Trace
Incorrect Stack Trace OMAP Code Optimization
OMAP Code Optimization No Component Symbols
No Component Symbols Insufficient Memory (committed memory)
Insufficient Memory (committed memory) Insufficient Memory (handle leak)
Insufficient Memory (handle leak) Insufficient Memory (kernel pool)
Insufficient Memory (kernel pool) Insufficient Memory (PTE)
Insufficient Memory (PTE) Insufficient Memory (module fragmentation)
Insufficient Memory (module fragmentation) Insufficient Memory (physical memory)
Insufficient Memory (physical memory) Insufficient Memory (control blocks)
Insufficient Memory (control blocks)- Insufficient Memory (reserved virtual memory)
- Insufficient Memory (session pool)
- Insufficient Memory (stack trace database)
- Insufficient Memory (region)
- Insufficient Memory (stack)
 Spiking Thread
Spiking Thread Module Variety
Module Variety Stack Overflow (kernel mode)
Stack Overflow (kernel mode) Stack Overflow (user mode)
Stack Overflow (user mode) Stack Overflow (software implementation)
Stack Overflow (software implementation)- Stack Overflow (insufficient memory)
- Stack Overflow (managed space)
 Managed Code Exception
Managed Code Exception- Managed Code Exception (Scala)
- Managed Code Exception (Python)
 Truncated Dump
Truncated Dump Waiting Thread Time (kernel dumps)
Waiting Thread Time (kernel dumps) Waiting Thread Time (user dumps)
Waiting Thread Time (user dumps) Memory Leak (process heap) - Modeling Example
Memory Leak (process heap) - Modeling Example Memory Leak (.NET heap)
Memory Leak (.NET heap)- Memory Leak (page tables)
- Memory Leak (I/O completion packets)
- Memory Leak (regions)
 Missing Thread (user space)
Missing Thread (user space)- Missing Thread (kernel space)
 Unknown Component
Unknown Component Double Free (process heap)
Double Free (process heap) Double Free (kernel pool)
Double Free (kernel pool) Coincidental Symbolic Information
Coincidental Symbolic Information Stack Trace
Stack Trace- Stack Trace (I/O request)
- Stack Trace (file system filters)
- Stack Trace (database)
- Stack Trace (I/O devices)
 Virtualized Process (WOW64)
Virtualized Process (WOW64)- Virtualized Process (ARM64EC and CHPE)
 Stack Trace Collection (unmanaged space)
Stack Trace Collection (unmanaged space)- Stack Trace Collection (managed space)
- Stack Trace Collection (predicate)
- Stack Trace Collection (I/O requests)
- Stack Trace Collection (CPUs)
 Coupled Processes (strong)
Coupled Processes (strong) Coupled Processes (weak)
Coupled Processes (weak) Coupled Processes (semantics)
Coupled Processes (semantics) High Contention (executive resources)
High Contention (executive resources) High Contention (critical sections)
High Contention (critical sections) High Contention (processors)
High Contention (processors)- High Contention (.NET CLR monitors)
- High Contention (.NET heap)
- High Contention (sockets)
 Accidental Lock
Accidental Lock Passive Thread (user space)
Passive Thread (user space) Passive System Thread (kernel space)
Passive System Thread (kernel space) Main Thread
Main Thread Busy System
Busy System Historical Information
Historical Information Object Distribution Anomaly (IRP)
Object Distribution Anomaly (IRP)- Object Distribution Anomaly (.NET heap)
 Local Buffer Overflow (user space)
Local Buffer Overflow (user space)- Local Buffer Overflow (kernel space)
 Early Crash Dump
Early Crash Dump Hooked Functions (user space)
Hooked Functions (user space) Hooked Functions (kernel space)
Hooked Functions (kernel space)- Hooked Modules
 Custom Exception Handler (user space)
Custom Exception Handler (user space) Custom Exception Handler (kernel space)
Custom Exception Handler (kernel space) Special Stack Trace
Special Stack Trace Manual Dump (kernel)
Manual Dump (kernel) Manual Dump (process)
Manual Dump (process) Wait Chain (general)
Wait Chain (general) Wait Chain (critical sections)
Wait Chain (critical sections) Wait Chain (executive resources)
Wait Chain (executive resources) Wait Chain (thread objects)
Wait Chain (thread objects) Wait Chain (LPC/ALPC)
Wait Chain (LPC/ALPC) Wait Chain (process objects)
Wait Chain (process objects) Wait Chain (RPC)
Wait Chain (RPC) Wait Chain (window messaging)
Wait Chain (window messaging) Wait Chain (named pipes)
Wait Chain (named pipes)- Wait Chain (mutex objects)
- Wait Chain (pushlocks)
- Wait Chain (CLR monitors)
- Wait Chain (RTL_RESOURCE)
- Wait Chain (modules)
- Wait Chain (nonstandard synchronization)
- Wait Chain (C++11, condition variable)
- Wait Chain (SRW lock)
 Corrupt Dump
Corrupt Dump Dispatch Level Spin
Dispatch Level Spin No Process Dumps
No Process Dumps No System Dumps
No System Dumps Suspended Thread
Suspended Thread Special Process
Special Process Frame Pointer Omission
Frame Pointer Omission False Function Parameters
False Function Parameters Message Box
Message Box Self-Dump
Self-Dump Blocked Thread (software)
Blocked Thread (software) Blocked Thread (hardware)
Blocked Thread (hardware)- Blocked Thread (timeout)
 Zombie Processes
Zombie Processes Wild Pointer
Wild Pointer Wild Code
Wild Code Hardware Error
Hardware Error Handle Limit (GDI, kernel space)
Handle Limit (GDI, kernel space)- Handle Limit (GDI, user space)
 Missing Component (general)
Missing Component (general) Missing Component (static linking, user mode)
Missing Component (static linking, user mode) Execution Residue (unmanaged space, user)
Execution Residue (unmanaged space, user)- Execution Residue (unmanaged space, kernel)
- Execution Residue (managed space)
 Optimized VM Layout
Optimized VM Layout- Invalid Handle (general)
- Invalid Handle (managed space)
- Overaged System
- Thread Starvation (realtime priority)
- Thread Starvation (normal priority)
- Duplicated Module
- Not My Version (software)
- Not My Version (hardware)
- Data Contents Locality
- Nested Exceptions (unmanaged code)
- Nested Exceptions (managed code)
- Affine Thread
- Self-Diagnosis (user mode)
- Self-Diagnosis (kernel mode)
- Self-Diagnosis (registry)
- Inline Function Optimization (unmanaged code)
- Inline Function Optimization (managed code)
- Critical Section Corruption
- Lost Opportunity
- Young System
- Last Error Collection
- Hidden Module
- Data Alignment (page boundary)
- C++ Exception
- Divide by Zero (user mode)
- Divide by Zero (kernel mode)
- Swarm of Shared Locks
- Process Factory
- Paged Out Data
- Semantic Split
- Pass Through Function
- JIT Code (.NET)
- JIT Code (Java)
- Ubiquitous Component (user space)
- Ubiquitous Component (kernel space)
- Nested Offender
- Virtualized System
- Effect Component
- Well-Tested Function
- Mixed Exception
- Random Object
- Missing Process
- Platform-Specific Debugger
- Value Deviation (stack trace)
- Value Deviation (structure field)
- Runtime Thread (CLR)
- Runtime Thread (Python, Linux)
- Coincidental Frames
- Fault Context
- Hardware Activity
- Incorrect Symbolic Information
- Message Hooks - Modeling Example
- Coupled Machines
- Abridged Dump
- Exception Stack Trace
- Distributed Spike
- Instrumentation Information
- Template Module
- Invalid Exception Information
- Shared Buffer Overwrite
- Pervasive System
- Problem Exception Handler
- Same Vendor
- Crash Signature
- Blocked Queue (LPC/ALPC)
- Fat Process Dump
- Invalid Parameter (process heap)
- Invalid Parameter (runtime function)
- String Parameter
- Well-Tested Module
- Embedded Comment
- Hooking Level
- Blocking Module
- Dual Stack Trace
- Environment Hint
- Top Module
- Livelock
- Technology-Specific Subtrace (COM interface invocation)
- Technology-Specific Subtrace (dynamic memory)
- Technology-Specific Subtrace (JIT .NET code)
- Technology-Specific Subtrace (COM client call)
- Dialog Box
- Instrumentation Side Effect
- Semantic Structure (PID.TID)
- Directing Module
- Least Common Frame
- Truncated Stack Trace
- Data Correlation (function parameters)
- Data Correlation (CPU times)
- Module Hint
- Version-Specific Extension
- Cloud Environment
- No Data Types
- Managed Stack Trace
- Managed Stack Trace (Scala)
- Managed Stack Trace (Python)
- Coupled Modules
- Thread Age
- Unsynchronized Dumps
- Pleiades
- Quiet Dump
- Blocking File
- Problem Vocabulary
- Activation Context
- Stack Trace Set
- Double IRP Completion
- Caller-n-Callee
- Annotated Disassembly (JIT .NET code)
- Annotated Disassembly (unmanaged code)
- Handled Exception (user space)
- Handled Exception (.NET CLR)
- Handled Exception (kernel space)
- Duplicate Extension
- Special Thread (.NET CLR)
- Hidden Parameter
- FPU Exception
- Module Variable
- System Object
- Value References
- Debugger Bug
- Empty Stack Trace
- Problem Module
- Disconnected Network Adapter
- Network Packet Buildup
- Unrecognizable Symbolic Information
- Translated Exception
- Regular Data
- Late Crash Dump
- Blocked DPC
- Coincidental Error Code
- Punctuated Memory Leak
- No Current Thread
- Value Adding Process
- Activity Resonance
- Stored Exception
- Spike Interval
- Stack Trace Change
- Unloaded Module
- Deviant Module
- Paratext
- Incomplete Session
- Error Reporting Fault
- First Fault Stack Trace
- Frozen Process
- Disk Packet Buildup
- Hidden Process
- Active Thread (Mac OS X)
- Active Thread (Windows)
- Critical Stack Trace
- Handle Leak
- Module Collection
- Module Collection (predicate)
- Deviant Token
- Step Dumps
- Broken Link
- Debugger Omission
- Glued Stack Trace
- Reduced Symbolic Information
- Injected Symbols
- Distributed Wait Chain
- One-Thread Process
- Module Product Process
- Crash Signature Invariant
- Small Value
- Shared Structure
- Thread Cluster
- False Effective Address
- Screwbolt Wait Chain
- Design Value
- Hidden IRP
- Tampered Dump
- Memory Fluctuation (process heap)
- Last Object
- Rough Stack Trace (unmanaged space)
- Rough Stack Trace (managed space)
- Past Stack Trace
- Ghost Thread
- Dry Weight
- Exception Module
- Reference Leak
- Origin Module
- Hidden Call
- Corrupt Structure
- Software Exception
- Crashed Process
- Variable Subtrace
- User Space Evidence
- Internal Stack Trace
- Distributed Exception (managed code)
- Thread Poset
- Stack Trace Surface
- Hidden Stack Trace
- Evental Dumps
- Clone Dump
- Parameter Flow
- Critical Region
- Diachronic Module
- Constant Subtrace
- Not My Thread
- Window Hint
- Place Trace
- Stack Trace Signature
- Relative Memory Leak
- Quotient Stack Trace
- Module Stack Trace
- Foreign Module Frame
- Unified Stack Trace
- Mirror Dump Set
- Memory Fibration
- Aggregated Frames
- Frame Regularity
- Stack Trace Motif
- System Call
- Stack Trace Race
- Hyperdump
- Disassembly Ambiguity
- Exception Reporting Thread
- Active Space
- Subsystem Modules
- Region Profile
- Region Clusters
- Source Stack Trace
- Hidden Stack
- Interrupt Stack
- False Memory
- Frame Trace
- Pointer Cone
- Context Pointer
- Pointer Class
- False Frame
- Procedure Call Chain
- C++ Object
- COM Exception
- Structure Sheaf
- Saved Exception Context (.NET)
- Shared Thread
- Spiking Interrupts
- Structure Field Collection
- Black Box
- Rough Stack Trace Collection (unmanaged space)
- COM Object
- Shared Page
- Exception Collection
- Dereference Nearpoint
- Address Representations
- Near Exception
- Shadow Stack Trace
- Past Process
- Foreign Stack
- Annotated Stack Trace
- Disassembly Summary
- Region Summary
- Analysis Summary
- Region Spectrum
- Normalized Region
- Function Pointer
- Interrupt Stack Collection
- DPC Stack Collection
- Dump Context
- False Local Address
- Encoded Pointer
- Latent Structure
- ISA-Specific Code
Pattern-Oriented LLM Context Management
In cooperation with GenAI, we propose a pattern language for managing, diagnosing, and repairing context in large language model (LLM) systems. Inspired by memory dump analysis, it reframes conversational state—token windows, KV-caches, retrievals, and transcripts—as observable artifacts that can be read, segmented, and reasoned about.
1. Conceptual Alignment
Memory dump analysis: we have a frozen system state (heap, stack, registers, handles). You need structured ways (patterns) to interpret what happened and where anomalies lie.
LLM context management: we have a dynamic, limited-window context (tokens in the prompt + generated continuation). We need structured strategies to maintain coherence, recall, and relevance across long or shifting interactions.
So, both are about:
- State representation
- Navigation across levels of abstraction
- Pattern recognition to interpret meaning
2. Pattern Families Reapplied to LLMs
Using the memory dump analysis taxonomy, we can draw analogies:
Structural patterns (e.g., "Stack Trace", "Heap Graph")
Context trace: The sequence of tokens, messages, or embeddings.
Analog: analyzing token “call stacks” to identify where topic drift began.
Temporal patterns (e.g., "Periodicity", "Error Burst")
Context lifecycle: Recognizing conversation cycles (e.g., Q → A → refinement).
Analog: "periodic error" becomes recurring hallucination in long-form dialogue.
Anomaly patterns (e.g., "Corruption", "Dangling Pointer")
Context corruption: Where injected noise or forgotten details lead to contradictions.
Analog: dangling reference = the model invents details not grounded in earlier context.
Diagnostic trajectory patterns (navigating from symptom to root cause)
Prompt engineering trajectory: iterative refinement of instructions to steer model back on track.
3. Higher-Order Mappings
Context window ≈ address space
Tokens in the active window = accessible memory; past truncated context = paged-out memory.
Embeddings ≈ symbolic heap objects
External vector memory is like mapped heap regions that can be dereferenced on demand.
Retrieval Augmented Generation (RAG) ≈ dump analysis with external symbol servers
Just as debuggers resolve addresses via symbol servers, RAG resolves context gaps via external knowledge.
Chain-of-Thought ≈ call stack
Each reasoning step corresponds to a frame in a diagnostic stack trace.
4. Pattern Language as Meta-Framework
Memory dump analysis pattern language gives a meta-taxonomy for LLM context management research:
- Failure patterns (e.g., hallucination loops, context bleed, token starvation).
- Navigational patterns (re-establishing grounding when context is partially lost).
- Architectural patterns (multi-agent context partitioning, like multi-process memory spaces).
This creates a portable, semiotic map of context phenomena across LLM frameworks.
5. Possible Research / Practical Outputs
LLM Context Forensics: Classify anomalies using memory dump patterns using dump-like snapshots of LLM state (KV-caches, attention matrices, prompt logs).
Context Debugger: An Interactive tool where you can “walk the stack” of a conversation, identify dangling references, or detect periodic error hallucinations.
Pattern Language Extension: Extend diagnostic patterns with LLM-specific categories (e.g., Prompt Poisoning, Embedding Drift, Attention Collapse).
Memory dump analysis pattern language is highly portable to LLM context management. It can serve as a meta-diagnostic and design language for classifying, predicting, and repairing LLM context failures, much like it systematized memory dump interpretation.
Source: ChatGPT 5 conversation
Pattern-Oriented Observability (Part 4): Diagnostics – Observability Square (DOS)
There is much confusion between diagnostics and observability (used in two senses). First, observability is a property, not a process. It concerns whether system internal states can be inferred from external outputs (observations) such as memory snapshots, traces, and logs. It is not enough to get a trace or memory dump file; these must be correctly engineered and procured using artifact acquisition patterns. The second usage of observability is to name a discipline.
What about a process? It is simply “observation”, a verb “observe” (previously called monitoring, which also has a second usage as a discipline), which is an inference from states to observations (nouns). We can do observations even if observability is not good, and get observations (observation results).
Correspondingly, diagnosability is a property. It is about whether we can infer instances of patterns of abnormal structure and behavior from observations by applying diagnostic analysis patterns.
Therefore, diagnostics is a process, too. We can perform diagnostics even if diagnosability is poor: we don’t get useful results for the subsequent root cause analysis or troubleshooting and debugging suggestions.
The following square shows relationships between these concepts:
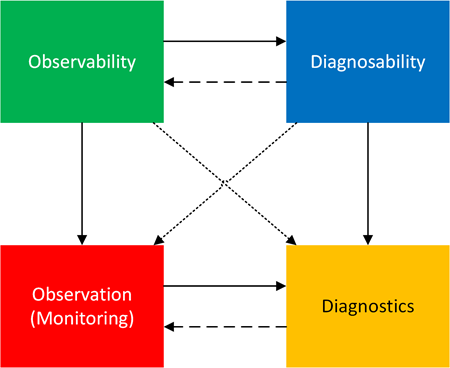
The top row shows the relationship between abstract properties (conditions): observability enables diagnosability, because only a limited amount of diagnosability is possible without observability. However, the critical use of diagnosability improves observability.
The bottom row shows that observation feeds into diagnostics and vice versa, since more observations may be required after diagnostics.
Columns show that observability is used in practice via observation, and diagnosability is used in practice via diagnostics.
What about diagonals?
Observability to diagnostics. If a system is observable, diagnostics are feasible: “If you can observe enough, you can perform diagnostics,” a sufficient condition for diagnostics.
Diagnosability to observation. Diagnosability implies constraints on observation: “If diagnostics are possible, then your observation process is strong enough,” a necessary condition for diagnosability.
Also, diagnostics can improve observability, and observations can improve diagnosability, but we do not show these arrows.
Although observability is distinct from diagnostics as seen from the diagram and explanation, it is considered a part of pattern-oriented and systemic diagnostics; this part, as a discipline (not a property), is called pattern-oriented observability.
Book: Accelerated .NET Memory Dump Analysis, Seventh Edition
The following direct links can be used to order the book now:
Available in PDF format with the optional recording from Software Diagnostics Technology and Services
Available in PDF format from Leanpub
Available in ultra-premium color paperback format from Amazon and Barnes & Noble
Available in Kindle print replica format from Amazon
The book is also included in the following training packs:
WinDbg Training Pack
Pattern-Oriented Windows Debugging Training Pack
Pattern-Oriented Complete Windows Memory Dump Analysis Training Pack
Complete Pattern-Oriented Software Diagnostics Training Pack
The full Software Diagnostics Services training transcript with 15 step-by-step exercises, notes, and source code of specially created modeling applications. The course covers 22 .NET memory dump analysis patterns, plus the additional 21 unmanaged patterns. Learn how to analyze .NET 9 application and service crashes and freezes, navigate through memory dump space (managed and unmanaged code), and diagnose corruption, leaks, CPU spikes, blocked threads, deadlocks, wait chains, resource contention, and more. The training consists of practical step-by-step exercises using WinDbg and LLDB debuggers to diagnose patterns in 64-bit process memory dumps from x64 Windows and x64 Linux environments. The training uses a unique and innovative pattern-oriented analysis approach to speed up the learning curve. The book is a completely revamped and extended the previous Accelerated .NET Core Memory Dump Analysis, Revised Edition. It is updated to the latest WinDbg. It also includes reviews of x64 and IL disassembly and memory space basics, Linux LLDB exercises, .NET memory dump collection on Windows and Linux, and the relationship of analysis patterns to defect mechanism patterns.
Prerequisites: Basic .NET programming and debugging.
Audience: Software technical support and escalation engineers, system administrators, DevOps, performance and reliability engineers, software developers, and quality assurance engineers. The book may also interest security researchers, reverse engineers, malware and memory forensics analysts.
- Title: Accelerated .NET Memory Dump Analysis: Training Course Transcript with WinDbg and LLDB Practice Exercises, Seventh Edition
- Authors: Dmitry Vostokov, Software Diagnostics Services, Dublin School of Security
- Publisher: OpenTask (May 2025)
- Language: English
- Product Dimensions: 28.0 x 21.6
- PDF: 324 pages
- ISBN-13: 978-1912636877

Table of Contents and Sample Exercise
Slides from the training
Online Training: Accelerated Windows Memory Dump Analysis
Software Diagnostics Services organizes this online training course.

Registration: Finished
For the approximate content, please see the slides from the previous training:
Slides from sessions 1-3
Slides from sessions 4-7
This training includes over 40 step-by-step exercises and covers over 100 crash dump analysis patterns from x64 process, kernel, and complete (physical) memory dumps. Learn how to analyze application, service, and system crashes and freezes, navigate through memory dump space, and diagnose heap corruption, memory leaks, CPU spikes, blocked threads, deadlocks, wait chains, and more with the WinDbg debugger. The training uses a unique and innovative pattern-oriented analysis approach developed by Software Diagnostics Institute to speed up the learning curve, and it is based on the latest 6th edition of the bestselling Accelerated Windows Memory Dump Analysis book. This new training version also includes:
- Overview of relevant Windows internals
- Memory dump collection methods and patterns
- Defect mechanism patterns
- Additional memory analysis patterns
- Extended coverage of BSOD
- Extended coverage of system hangs
- New kernel exercises with source code
Before the training, you get:
- Practical Foundations of Windows Debugging, Disassembling, Reversing, Third Edition PDF book
- The current PDF book version
- The previous training recording
- Access to Software Diagnostics Library with more than 440 cross-referenced patterns of memory dump analysis, their classification, and more than 70 case studies
After the training, you also get:
- The new 7th PDF book edition
- Personalized Certificate of Attendance with unique CID
- Optional Personalized Certificate of Completion with unique CID (after the tests)
- Answers to questions during training sessions
- New training sessions recording
Prerequisites: Basic Windows troubleshooting
Audience: Software technical support and escalation engineers, system administrators, security and vulnerability researchers, reverse engineers, malware and memory forensics analysts, DevSecOps and SRE, software developers, and quality assurance engineers.
If you are mainly interested in .NET memory dump analysis, there is another training: Accelerated .NET Memory Dump Analysis
If you are interested in Linux memory dump analysis, there is another training: Accelerated Linux Core Dump Analysis
Book: Practical Foundations of Windows Debugging, Disassembling, Reversing, Third Edition
The following direct links can be used to order the book now:
Available in PDF format with the optional recording, the previous edition (x86 32-bit chapters), and training slides from Software Diagnostics Services
Available in PDF format from Leanpub
Available in ultra-premium color paperback format from Amazon and Barnes & Noble
Available in Kindle print replica format from Amazon
The previous edition (x86 32-bit chapters) is also available in Kindle print replica format from Amazon or in PDF format from Leanpub
The book is also included in most training courses and training packs:
Training Courses
This training course is a reformatted, improved, and modernized version of the previous x64 Windows Debugging: Practical Foundations book, which drew inspiration from the original lectures we developed 22 years ago to train support and escalation engineers in debugging and crash dump analysis of memory dumps from Windows applications, services, and systems. At that time, when thinking about what material to deliver, we realized that a solid understanding of fundamentals like pointers is needed to analyze stack traces beyond a few WinDbg commands. Therefore, this book is not about bugs or debugging techniques but about the background knowledge everyone needs to start experimenting with WinDbg, learn from practical experience, and read other advanced debugging books. This body of knowledge is what the author of this book possessed before starting memory dump analysis using WinDbg 18 years ago, which resulted in the number one debugging bestseller: the multi-volume Memory Dump Analysis Anthology (Diagnomicon). Now, in retrospection, we see these practical foundations as relevant and necessary to acquire for beginners as they were more than 20 years ago, because operating systems internals, assembly language, and compiler architecture haven't changed much in those years.
The third edition, with new material on arrays and floating point, was completely remastered in full color. The text was also reviewed, and a few previous mistakes were corrected. The book is also slimmer because the x86 32-bit chapters were removed. They are still available in the previous edition, which will not be out of print soon. The third edition is entirely x64.
The book is useful for:
- Software technical support and escalation engineers
- Software engineers coming from a managed code or JVM background
- Software testers
- Engineers coming from non-Wintel environments
- Windows C/C++ software engineers without an assembly language background
- Security researchers without an x64 assembly language background
- Beginners learning Windows software reverse engineering techniques
This introductory training course can complement the more advanced Accelerated Disassembly, Reconstruction, and Reversing course. It may also help with advanced exercises in Accelerated Windows Memory Dump Analysis, Accelerated Rust Windows Memory Dump Analysis, Accelerated Windows Debugging4, Accelerated Windows API for Software Diagnostics, Accelerated Windows Malware Analysis with Memory Dumps, and Memory Thinking books for C and C++. This book can also be used as an Intel assembly language and Windows debugging supplement for relevant undergraduate-level courses.
Product information:
- Title: Practical Foundations of Windows Debugging, Disassembling, Reversing: Training Course, Third Edition
- Authors: Dmitry Vostokov, Software Diagnostics Services, Dublin School of Security
- Language: English
- Product Dimensions: 28.0 x 21.6
- PDF/Paperback: 178 pages
- Publisher: OpenTask (July 2025)
- ISBN-13: 978-1912636471

For the history of the book, please see the first 20 slides (there are almost 200 slides for the training).
Pattern-Oriented Observability (Part 3): Observation Spaces

There are many spaces where we do our observations in software systems. The explosion of spaces began with the Abstract Space, where we depict running threads as braids.
When we talk about spaces, we also consider suitable space metrics (not to be mistaken with observability metrics below) by which we can compare the proximity of space objects.
In diagnostics, we have the so-called Diagnostic Spaces with their signals, symptoms, syndromes, and signs. Different analysis patterns can serve the role of space metrics in pattern-oriented software forensics, diagnostics, and prognostics.
Traces, logs, and metrics are pillars of observability that are all erected from Memory Space and, therefore, can be considered Adjoint Spaces. Memory spaces are also diverse: including manifold, orbifold, hyperphysical, physical, virtual, kernel, user, managed, and secondary, and have their own large-scale structures.
Traces and logs have their own individual Trace and Log Spaces (including Message Spaces, Interspaces, and Tensor Spaces. These also include network traces and logs from memory debuggers. (Observability) Metrics Spaces are a subtype of such spaces.
Traces and logs are also examples of the so-called software narratives with their own Software Narrative Spaces, including higher-level narratives, and space-like narratology. We can also consider software diagnostic spaces as general graphs of software narratives.
If we are concerned with the hardware-software interface, then we can consider Hardware Spaces via hardware narratology.
Presentation Spaces visualize other spaces, and visualization languages help with their meaning.
We analyze all these spaces to identify patterns with the help of analysis patterns, which are organized in their own Analysis Patterns Space (memory and traces).
Defect Mechanism Spaces help in root cause analysis.
When we delve into software workings, we are concerned with Software Internal Spaces.
Additionally, we have various Namespaces, Code Spaces (similar to Declarative Trace Spaces), State Spaces, and Data Spaces.
Artificial Chemistry Spaces based on the idea of spaces of chemistry enhance the artificial chemistry approach to trace and log analysis.
For many years, the ideas of various physical and mathematical spaces have inspired diverse memory and log analysis patterns, as well as some concepts in software diagnostics and software data analysis.
We would also like to mention that the book that introduces Information Space is featured on the cover of this article.
And finally, the new wave of AI suggests Token Spaces.
Memory Dump Analysis Pattern Classification
A partial classification of memory analysis patterns from Software Diagnostics Library pattern catalogue:
- Space/Mode
- Memory dump type
- Hooksware
- Wait Chain Patterns
- DLL Link Patterns
- Memory Consumption Patterns
- Dynamic Memory Corruption Patterns
- Deadlock and Livelock Patterns
- Contention Patterns
- Stack Overflow Patterns
- .NET / CLR / Managed Space Patterns
- Stack Trace Patterns
- Symbol Patterns
- Exception Patterns
- Meta-Memory Dump Patterns
- Module Patterns
- Optimization Patterns
- Thread Patterns
- Process Patterns
- Executive Resource Patterns
- Falsity and Coincidence Patterns
- RPC, LPC and ALPC Patterns
- Hidden Artifact Patterns
- Pointer Patterns
- Frame Patterns
- CPU Consumption Patterns
- Region Patterns
- Collection Patterns
Pattern-Oriented Observability (Part 2): Semiotics of Memory, Trace, and Log Analysis

Memory analysis icons were introduced more than 15 years ago, in March 2010, as part of computer memory semiotics (memiotics). Over the next year and a half, 101 icons were created (with black and white equivalents). These iconic representations are both icons and indexes in the sense of Pierce’s three types of signs: icon signs resemble artifacts or the current state of affairs, and index signs have some causal or relationship connection through interpretation. More than two years ago, in March 2023, we introduced Iconic Traces. These traces also consist of iconic representations that are both indexical and iconic signs, as they resemble the patterns, syntactic, semantic, and pragmatic content of trace messages, message blocks, and applied trace analysis patterns. The Dia|gram language (introduced in 2016) pictures are another great example of complex iconic (structure) and indexical (behavior, observation, measurement) signs (including memory). The Space-like Narratology and the Lov language further extend the semiotic approach.
Situational Awareness in Pattern-Oriented Software Diagnostics, Forensics, Prognostics
Situational awareness is defined as "the understanding of an environment, its elements, and how it changes with respect to time or other factors. It is also defined as the perception of the elements in the environment considering time and space, the understanding of their meaning, and the prediction of their status in the near future."
How does it fit into software diagnostics, which is often incorrectly perceived as an analysis of the past (which is forensics)? To answer this question with examples from pattern-oriented software diagnostics (and forensics and prognostics), we should map the three levels of situational awareness (Endsley's model):
Perception – noticing key environmental forensic, diagnostic, and prognostic elements: symptoms, signs, syndromes, alerts, anomalies, and counters.
Comprehension – understanding the situation, what’s going wrong and what’s going on at the particular moment in time and place in memory space (and trace space), and what those key elements mean in current (and past) local immediate and wider big-picture context: software internals and analysis patterns (Fault Context, Message Context, Dump Context, Activity Context, Trace Context), whether they are related to a potential root cause or just surface phenomena (Effect Component). Here, attention to detail is very important.
Projection – anticipating the future: how the situation would have evolved if we had collected diagnostic artifacts later, for example, Near Exception, or the environment had changed (Changed Environment), and plenty of trace and log analysis patterns related to prognostics. It also includes avoiding unintended side effects when acting (providing recommendations), for example, the Instrumentation Side Effect.
In summary, situational awareness in software diagnostics, forensics, and prognostics involves maintaining an appropriate mental model of the system as seen from forensics and diagnostic artifacts (including live ones) and continuous perception, understanding, and anticipation of the system's state, anomalies, potential not-yet-discovered patterns, and future failures while performing a diagnostic (forensic, prognostic) analysis.
Pattern-Oriented Observability (Part 1): The Base Slab and Foundation of Observability Pillars
Metrics, logs, and traces are considered traditional pillars of observability. However, what is the base they stand upon? It is memory. In 2009, I defined software traces as fragments of memory since they are all assembled in memory first (Software Trace: A Mathematical Definition, Memory Dump Analysis Anthology, Volume 3). Also, every trace or log message had some corresponding memory state(s) at the time it was generated, the so-called Adjoint Space trace and log analysis pattern (Volume 8b), and memory state may have traces and logs erected on its pedestal if we talk about classic memory dump analysis, the so-called Memory Fibration analysis pattern (Volume 10). These two analysis patterns are a kind of duality between memory and traces, the so-called De Broglie Trace Duality (Volume 10). Also, what about trace and log’s own memory? Based on the growing block universe theory analogy, any chosen trace message may be considered trace's present, and everything before it as trace’s past. We can also consider trace and log as memory to predict future behavior, next trace and log messages, and metrics’ values (the so-called process time perspective).
A note about the chosen terminology: base slab or foundation is used in modern structural design. If some prefer classical architecture, we can use stylobate or podium terminology. For each pillar, we can have a corresponding memory plinth.
Memory Thinking for Rust, Second Edition
The following direct links can be used to order the book now:
Available in PDF format with the optional recording and Windows/Linux API books from Software Diagnostics Technology and Services
Available in PDF format from Leanpub
Available in ultra-premium color paperback format from Amazon and Barnes & Noble
Available in Kindle print replica format from Amazon
The book is also included in the following training courses, training packs, and reference sets:
Pattern-Oriented Software Diagnostics and Anomaly Detection Reference Set
Accelerated Rust Windows Memory Dump Analysis
GDB Training Pack
Complete Pattern-Oriented Software Diagnostics Training Pack

Memory Thinking for Rust training reviews memory-related topics from the perspective of software structure and behavior analysis and teaches Rust language aspects in parallel while demonstrating relevant code internals using WinDbg and GDB on Windows (x64) and Linux (x64 and ARM64) platforms:
- Relevant language constructs
- Memory layout of structs and enums
- References, ownership, borrowing, and lifecycle
- Local, static, and dynamic memory
- Functions, closures
- Smart pointers
- Object-oriented and functional features
- Unsafe pointers
- Windows and Linux specifics
- … and much more
The new training version updates and extends the existing topics, adding some missing from the first edition. The updated PDF book also has a new format similar to the second edition of Memory Thinking books for C and C++.
The training includes the PDF book that contains slides, brief notes highlighting particular points, and related source code with execution output:
- Title: Memory Thinking for Rust: Slides with Descriptions and Source Code Illustrations, Second Edition
- Authors: Dmitry Vostokov, Software Diagnostics Services, Dublin School of Security
- Publisher: OpenTask (April 2025)
- Language: English
- Product Dimensions: 25.4 x 20.3
- PDF: 272 pages
- ISBN-13: 978-1912636488
The following audiences may benefit from the training:
- Rust developers who want to deepen their knowledge
- Non-C and C++ developers (for example, Java, Scala, Python) who want to learn more about pointer and reference internals
- C and C++ developers who want to port their memory thinking to Rust quickly
For more detailed content, please see the first 15 slides (there are more than 240 slides for the training and 2,500 lines of Rust code) and Table of Contents from the reference book.
Book: Accelerated Linux Core Dump Analysis, Fourth Edition
The following direct links can be used to order the book now:
Available in PDF and ultra-premium color paperback formats with recording from Software Diagnostics Technology and Services
Available in PDF format from Leanpub
Available in ultra-premium color paperback format from Amazon and Barnes & Noble
Available in Kindle print replica format from Amazon
The book is also included in the following training packs:
GDB Training Pack
WinDbg Training Pack
Pattern-Oriented Unix Memory Dump Analysis Training Pack
Pattern-Oriented Memory Dump Analysis Training Pack
Pattern-Oriented Linux Debugging Training Pack
Foundations of Linux Memory Dump Analysis Training Pack
Linux Memory Dump Analysis for Endpoint Security Training Pack
Pattern-Oriented Memory Dump Analysis Training Pack
Complete Pattern-Oriented Software Diagnostics Training Pack
The full transcript of Software Diagnostics Services training. Learn how to analyze Linux process and kernel crashes and hangs, navigate through core memory dump space, and diagnose corruption, memory leaks, CPU spikes, blocked threads, deadlocks, wait chains, and much more. This training uses a unique and innovative pattern-oriented diagnostic analysis approach to speed up the learning curve. The training consists of more than 70 practical step-by-step exercises using GDB and WinDbg debuggers, highlighting more than 50 memory analysis patterns diagnosed in 64-bit core memory dumps from x64 and ARM64 platforms. The training also includes source code of modeling applications, a catalog of relevant patterns from the Software Diagnostics Institute, and an overview of relevant similarities and differences between Windows and Linux memory dump analysis useful for engineers with a Wintel background. In addition to various improvements, the fully revised and updated fourth edition adds entirely new material, such as defect mechanism patterns and WinDbg Linux kernel dump analysis exercises.
- Title: Accelerated Linux Core Dump Analysis: Training Course Transcript with GDB and WinDbg Practice Exercises, Fourth Edition
- Authors: Dmitry Vostokov, Software Diagnostics Services, Dublin School of Security
- Publisher: OpenTask (January 2025)
- Language: English
- PDF/Paperback: 737 pages
- ISBN-13: 978-1912636495

Table of Contents and Sample Exercise
Slides from the training
Book: Accelerated Windows API for Software Diagnostics, Second Edition
The following direct links can be used to order the book now:
Available in PDF format with the optional recording and Memory Dump Analysis Anthology from Software Diagnostics Technology and Services
Available in PDF format from Leanpub
Available in ultra-premium color paperback format from Amazon and Barnes & Noble
Available in Kindle print replica format from Amazon
The book is also included in the following training courses and training packs:
WinDbg Training Pack
Foundations of Windows Memory Dump Analysis Training Pack
System API Patterns for Software Diagnostics Training Pack
Accelerated C & C++ for Windows Diagnostics
Accelerated Rust Windows Memory Dump Analysis
Memory Thinking for Rust
Complete Pattern-Oriented Software Diagnostics Training Pack
The book contains the full Software Diagnostics Services training transcript with 10 hands-on exercises.
Knowledge of Windows API is necessary for:
- Development
- Malware analysis
- Vulnerability analysis and exploitation
- Reversing
- Diagnostics
- Debugging
- Memory forensics
- Crash and hang analysis
- Secure coding
- Static code analysis
- Trace and log analysis
The training uses a unique and innovative pattern-oriented analysis approach and provides:
- Overview
- Classification
- Patterns
- Internals
- Development examples
- Analysis examples
The second edition includes the relevant x64 disassembly overview and additional topics.

- Title: Accelerated Windows API for Software Diagnostics: With Category Theory in View, Second Edition
- Authors: Dmitry Vostokov, Software Diagnostics Services, Dublin School of Security
- Publisher: OpenTask (December 2024)
- Language: English
- Product Dimensions: 28.0 x 21.6
- PDF: 329 pages
- ISBN-13: 978-1912636884
Table of Contents and sample exercise
Slides from the training
Book: Accelerated Rust Windows Memory Dump Analysis
The following direct links can be used to order the book now:
Available in PDF format with the optional recording and Windows API and Memory Thinking for Rust books from Software Diagnostics Technology and Services
Available in PDF format from Leanpub
Available in ultra-premium color paperback format from Amazon and Barnes & Noble
Available in Kindle print replica format from Amazon
The book is also included in the following training courses, training packs, and reference sets:
WinDbg Training Pack
Complete Pattern-Oriented Software Diagnostics Training Pack
The book contains the full Software Diagnostics Services training transcript and 10 step-by-step exercises and covers dozens of crash dump analysis patterns from the x64 process and complete (physical) memory dumps. Learn how to analyze Rust application crashes and freezes, navigate through memory dump space, and diagnose heap corruption, memory leaks, CPU spikes, blocked threads, deadlocks, wait chains, and much more with the WinDbg debugger. The training uses a unique and innovative pattern-oriented analysis approach developed by the Software Diagnostics Institute to speed up the learning curve, and it is structurally based on the latest 6th revised edition of the bestselling Accelerated Windows Memory Dump Analysis book with the focus on safe and unsafe Rust code and its interfacing with the Windows OS. The training is useful whether you come to Rust from C and C++ or interpreted languages like Python and facilitates memory thinking when programming in Rust.
Prerequisites: Basic Windows troubleshooting and working knowledge of Rust.
Audience: Software technical support and escalation engineers, system administrators, security and vulnerability researchers, reverse engineers, malware and memory forensics analysts, DevSecOps and SRE, software developers, system programmers, and quality assurance engineers.
- Title: Accelerated Rust Windows Memory Dump Analysis
- Authors: Dmitry Vostokov, Software Diagnostics Services, Dublin School of Security
- Publisher: OpenTask (December 2024)
- Language: English
- Product Dimensions: 28.0 x 21.6
- PDF: 233 pages
- ISBN-13: 978-1912636891

Table of Contents and sample exercise
Slides from the training
Book: Extended Windows Memory Dump Analysis, Second Edition
The following direct links can be used to order the book now:
Available in PDF format with the optional recording and Memory Dump Analysis Anthology from Software Diagnostics Technology and Services
Available in PDF format from Leanpub
Available in ultra-premium color paperback format from Amazon and Barnes & Noble
Available in Kindle print replica format from Amazon
The book is also included in the following training courses, training packs, and reference sets:
WinDbg Training Pack
Complete Pattern-Oriented Software Diagnostics Training Pack
The book contains the full transcript of Software Diagnostics Services training with 25 hands-on exercises. This training course extends pattern-oriented analysis introduced in Accelerated Windows Memory Dump Analysis, Accelerated .NET Core Memory Dump Analysis, and Advanced Windows Memory Dump Analysis with Data Structures courses with:
- Surveying the current landscape of WinDbg extensions with analysis pattern mappings
- Writing WinDbg extensions in C, C++, and Rust (new)
- Connecting WinDbg to NoSQL databases
- Connecting WinDbg to streaming and log processing platforms
- Querying and visualizing WinDbg output data
- Using Data Science, Machine Learning, and Gen AI for diagnostics and postmortem debugging (new)
The new edition of the training updates existing exercises and includes new ones.
Prerequisites: Working knowledge of WinDbg. Working knowledge of C, C++, or Rust is optional (required only for some exercises). Other concepts are explained when necessary.
Audience: Software developers, software maintenance engineers, escalation engineers, quality assurance engineers, security and vulnerability researchers, malware and memory forensics analysts who want to build memory analysis pipelines.
- Title: Extended Windows Memory Dump Analysis: Using and Writing WinDbg Extensions, Database and Event Stream Processing, Data Science and Visualization, Machine Learning and AI, Second Edition
- Authors: Dmitry Vostokov, Software Diagnostics Services
- Publisher: OpenTask (November 2024)
- Language: English
- Product Dimensions: 28.0 x 21.6
- PDF: 362 pages
- ISBN-13: 978-1912636518

Table of Contents and sample exercise
Slides from the training
Memory Thinking for C & C++ Linux Diagnostics, Second Edition
The following direct links can be used to order the book now:
Available in PDF format from Software Diagnostics Technology and Services
Available in PDF format from Leanpub
Available in ultra-premium color paperback format from Amazon and Barnes & Noble
Available in Kindle print replica format from Amazon
The book is also included in the following training courses, training packs, and reference sets:
Pattern-Oriented Software Diagnostics and Anomaly Detection Reference Set
Accelerated C & C++ for Linux Diagnostics
Memory Thinking for C and C++ Training Pack
Foundations of Linux Memory Dump Analysis Training Pack
GDB Training Pack
Complete Pattern-Oriented Software Diagnostics Training Pack
Solid C and C++ knowledge is a must to fully understand Linux diagnostic artifacts such as core memory dumps and perform diagnostic, forensic, and root cause analysis beyond listing backtraces. This full-color reference book is a part of the Accelerated C & C++ for Linux Diagnostics training course organized by Software Diagnostics Services. The text contains slides, brief notes highlighting particular points, and source code illustrations. In addition to new topics, the second edition adds 45 projects with more than 5,500 lines of code. The book's detailed Table of Contents makes the usual Index redundant. We hope this reference is helpful for the following audiences:
- C and C++ developers who want to deepen their knowledge
- Software engineers developing and maintaining products on Linux platforms
- Technical support, escalation, DevSecOps, cloud, and site reliability engineers dealing with complex software issues
- Quality assurance engineers who test software on Linux platforms
- Security and vulnerability researchers, reverse engineers, malware and memory forensics analysts

- Title: Memory Thinking for C & C++ Linux Diagnostics: Slides with Descriptions and Source Code Illustrations, Second Edition
- Authors: Dmitry Vostokov, Software Diagnostics Services, Dublin School of Security
- Language: English
- Product Dimensions: 25.4 x 20.3
- PDF: 292 pages
- Publisher: OpenTask (October 2024)
- ISBN-13: 978-1912636563
Table of Contents
The first 45 slides from the training (there are 297 slides in total)
Online Training: Writing Bad Code (Part 1)
Software Diagnostics Services organizes this online training course.

Registration: TBD
Why would you need to learn how to write bad code? Of course, not to write malicious code backdoors, but to understand software internals and diagnostics better. Writing "good" bad code is not easy, especially if you put specific requirements on it and are not satisfied with the accidental effects of "bad" bad code.
Topics include:
- Modeling abnormal software behavior
- Modeling memory analysis patterns
- Modeling trace and log analysis patterns
- Modeling defect mechanism patterns
- Simulation of complex software problems
- Software problem design patterns
- Fault injection
- Excellent bad code
- Portable bad code
- User and kernel code
- Avoiding compiler undefined behavior
- Debugging bad code to make it work as intended
The training also includes numerous hands-on coding projects using Visual C & C++ and GNU C & C++ compilers, x64 Windows, and x64 and ARM64 Linux platforms. Some parts will also use Python, C#, Rust, and Scala for modeling examples.
Before the training, you get:
- Practical Foundations of Windows Debugging, Disassembling, Reversing, Second Edition PDF book (+300 pages)
- Encyclopedia of Crash Dump Analysis Patterns, Third Edition (1,300 pages)
- Trace, Log, Text, Narrative, Data: An Analysis Pattern Reference for Information Mining, Diagnostics, Anomaly Detection, Fifth Edition (400 pages)
- Access to Software Diagnostics Library with more than 440 cross-referenced patterns of memory dump analysis, their classification, more than 70 case studies, and more than 240 general trace and log analysis patterns
After the training, you also get:
- The PDF book version of the training
- Personalized Certificate of Attendance with unique CID
- Recording
If you complete all parts, you will also get the fourth edition of the Encyclopedia of Crash Dump Analysis Patterns once it is available.
Audience:
C and C++ developers, Windows and Linux system programmers, software technical support and escalation engineers, system administrators, security and vulnerability researchers, reverse engineers, malware and memory forensics analysts, software developers, and quality assurance engineers.
Memory Thinking for C & C++ Windows Diagnostics, Second Edition
The following direct links can be used to order the book now:
Available in PDF format from Software Diagnostics Technology and Services
Available in PDF format from Leanpub
Available in ultra-premium color paperback format from Amazon and Barnes & Noble
Available in Kindle print replica format from Amazon
The book is also included in the following training courses, training packs, and reference sets:
Pattern-Oriented Software Diagnostics and Anomaly Detection Reference Set
Accelerated C & C++ for Windows Diagnostics
Memory Thinking for C and C++ Training Pack
Foundations of Windows Memory Dump Analysis Training Pack
WinDbg Training Pack
Complete Pattern-Oriented Software Diagnostics Training Pack
Solid C and C++ knowledge is a must to fully understand Windows diagnostic artifacts, such as memory dumps, and perform diagnostic, forensic, and root cause analysis beyond listing stack traces, DLLs, and driver information. This full-color reference book is a part of the Accelerated C & C++ for Windows Diagnostics training course organized by Software Diagnostics Services. The text contains slides, brief notes highlighting particular points, and illustrative source code fragments. The second edition added 45 Visual Studio projects with more than 5,500 lines of code. The book's detailed Table of Contents makes the usual Index redundant. The book's detailed Table of Contents makes the usual Index redundant. We hope this reference is helpful for the following audiences:
- C and C++ developers who want to deepen their knowledge
- Software engineers developing and maintaining products on Windows platforms
- Technical support, escalation, DevSecOps, cloud and site reliability engineers dealing with complex software issues
- Quality assurance engineers who test software on Windows platforms
- Security and vulnerability researchers, reverse engineers, malware and memory forensics analysts

- Title: Memory Thinking for C & C++ Windows Diagnostics: Slides with Descriptions and Source Code Illustrations, Second Edition
- Authors: Dmitry Vostokov, Software Diagnostics Services, Dublin School of Security
- Language: English
- Product Dimensions: 25.4 x 20.3
- PDF: 272 pages
- Publisher: OpenTask (July 2024)
- ISBN-13: 978-1912636617
Table of Contents
The first 56 slides from the training (there 289 slides in total)
Book: Accelerated Linux Debugging 4D
The following direct links can be used to order the book now:
Available in PDF format with the optional recording and Linux API book from Software Diagnostics Technology and Services
Available in PDF format from Leanpub
Available in ultra-premium color paperback format from Amazon and Barnes & Noble
Available in Kindle print replica format from Amazon
The book is also included in the following training courses, training packs, and reference sets:
Linux Debugging Training Pack
GDB Training Pack
Complete Pattern-Oriented Software Diagnostics Training Pack

Table of Contents and Sample Exercise
Slides from the training
The full transcript of Software Diagnostics Services training with more than 20 step-by-step exercises using WSL and Hyper-V environments, notes, and source code of specially created modeling applications in C, C++, and Rust. Learn live local and remote debugging techniques in the kernel, user process, and managed spaces using WinDbg, GDB, LLDB, rr, and KDB, KGDB debuggers. The unique and innovative course teaches unified debugging patterns applied to real problems from complex software environments. A necessary x64 and ARM64 review is also included.
Prerequisites: Working knowledge of one of these languages: C, C++, Rust. Operating system internals and assembly language concepts are explained when necessary.
Audience: Software engineers, software maintenance engineers, escalation engineers, SRE, DevOps and DevSecOps, cloud engineers, security and vulnerability researchers, malware and memory forensics analysts who want to learn live memory inspection techniques.
- Title: Accelerated Linux Debugging4: Training Course Transcript with WinDbg, GDB, LLDB, rr, KDB, KGDB Practice Exercises
- Authors: Dmitry Vostokov, Software Diagnostics Services
- Publisher: OpenTask (July 2024)
- Language: English
- Product Dimensions: 28.0 x 21.6
- PDF: 360 pages
- ISBN-13: 978-1912636716
Declarative Memory
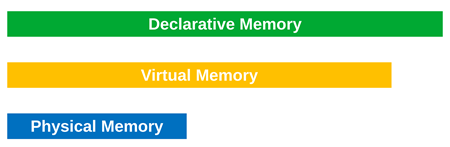
In addition to physical and virtual memory layers, we add another abstraction, the memory layer associated with source code values. We call it declarative memory. This term is not to be confused with declarative (or explicit) memory in neuropsychology. Memory corresponding to values in source code may be linearly organized but translated to a different layout by a compiler, or different values can be translated to the same virtual memory location. For example, in Rust (which prompted us to introduce this new memory concept), the following tuple is mapped to a different memory layout:
let i: i32 = 1;
let tuple: (bool, i32, &i32) = (true, 0, &i);
0:000> dt tuples!tuple Local var @ 0x5c3196f2f0 Type tuple$<bool,i32,ref$<i32> > +0x004 __0 : 1 +0x000 __1 : 0n0 +0x008 __2 : 0x0000005c`3196f2ec -> 0n1
0:000> dq 0x5c3196f2f0 L2 0000005c`3196f2f0 00000001`00000000 0000005c`3196f2ec
0:000> dd 0x5c3196f2f0 L4 0000005c`3196f2f0 00000000 00000001 3196f2ec 0000005c
Another virtual memory cell reuse example is the Optimized Code (function parameter reuse) memory analysis pattern.
Whereas in trace and log analysis, where there is the Declarative Trace analysis pattern where a declarative trace statement in source code may correspond to many actual trace statements, a kind of 1 to 0..N correspondence, declarative memory is usually M to N, where M >= N.
Similar to virtual-to-physical mapping, where the amount of virtual memory is greater than the amount of physical memory, the amount of declarative memory can be greater than the amount of virtual memory.
Memory Dump Analysis Anthology, Volume 16
The following direct links can be used to order the book now:
Available in PDF format from Software Diagnostics Technology and Services
Available in PDF format from Leanpub
Available in ultra-premium color paperback format from Amazon and Barnes & Noble
Available in Kindle print replica format from Amazon
The book is also included in the following training courses, training packs, and reference sets:
Memory Dump Analysis Anthology Volume Set (Diagnomicon)
Advanced Windows Memory Dump Analysis with Data Structures
Pattern-Oriented Software Diagnostics and Anomaly Detection Reference Set
Pattern-Oriented Windows Victimware Analysis Training Pack
Pattern-Oriented Windows Crash Dump Analysis Training Pack
Pattern-Oriented Windows Memory Forensics Training Pack
Windows Memory Dump Analysis for Endpoint Security Training Pack
Pattern-Oriented Complete Windows Memory Dump Analysis Training Pack
Complete Pattern-Oriented Software Diagnostics Training Pack
This reference volume consists of revised, edited, cross-referenced, and thematically organized selected articles from Software Diagnostics Institute (DumpAnalysis.org + TraceAnalysis.org) and Software Diagnostics Library (former Crash Dump Analysis blog, DumpAnalysis.org/blog) about software diagnostics, root cause analysis, debugging, crash and hang dump analysis, software trace and log analysis written from 15 April 2023 to 14 April 2024 for software engineers developing and maintaining products on Windows platforms, quality assurance engineers testing software, technical support, DevOps and DevSecOps, escalation and site reliability engineers dealing with complex software issues, security and vulnerability researchers, reverse engineers, malware and memory forensics analysts. This volume is fully cross-referenced with volumes 1 – 15 and features:
- 17 new crash dump analysis patterns
- 13 new software trace and log analysis patterns
- New defect mechanism pattern
- Introduction to Lov language
- Lists of recommended books
Product information:
- Title: Memory Dump Analysis Anthology, Volume 16
- Authors: Dmitry Vostokov, Software Diagnostics Institute
- Language: English
- Product Dimensions: 22.86 x 15.24
- Paperback: 170 pages
- Publisher: OpenTask (April 2024)
- ISBN-13: 978-1-912636-16-7

Book: Advanced Windows Memory Dump Analysis with Data Structures, Fifth Edition
The following direct links can be used to order the book now:
Available in PDF format with the recording and optional Memory Dump Analysis Anthology from Software Diagnostics Technology and Services
Available in PDF format from Leanpub
Available in ultra-premium color paperback format from Amazon and Barnes & Noble
Available in Kindle print replica format from Amazon
The book is also included in the following training packs:
WinDbg Training Pack
Pattern-Oriented Windows Crash Dump Analysis Training Pack
Pattern-Oriented Windows Memory Forensics Training Pack
Windows Memory Dump Analysis for Endpoint Security Training Pack
Pattern-Oriented Complete Windows Memory Dump Analysis Training Pack
Complete Pattern-Oriented Software Diagnostics Training Pack
The full transcript of the Software Diagnostics Services training course with 16 step-by-step exercises, notes, and selected questions and answers. Learn how to navigate through memory dump space and Windows data structures to diagnose, troubleshoot, and debug complex software incidents. The training uses a unique and innovative pattern-oriented analysis approach to speed up the learning curve. It consists of practical step-by-step exercises using WinDbg to diagnose structural and behavioral patterns in the 64-bit kernel and complete (physical) memory dumps. Additional topics include memory search, kernel linked list navigation, practical WinDbg scripting, registry, system variables and objects, device drivers, and I/O. Prerequisites are basic and intermediate level Windows memory dump analysis: the ability to list processors, processes, threads, modules, apply symbols, walk through stack traces and raw stack data, diagnose patterns such as heap corruption, CPU spike, memory leaks, access violation, wait chains and deadlocks. If you don't feel comfortable with prerequisites, then Accelerated Windows Memory Dump Analysis training book is recommended before purchasing and reading this book course. Audience: Software technical support and escalation engineers, system administrators, security researchers, reverse engineers, malware and memory forensics analysts, software developers, and quality assurance engineers. The fifth edition uses the latest WinDbg, includes the relevant Unified Modeling Language tutorial, revised and extended existing exercises, and added the exercise that demonstrates the use of a Generative AI LLM assistant.
- Title: Advanced Windows Memory Dump Analysis with Data Structures: Training Course Transcript and WinDbg Practice Exercises with Notes, Fifth Edition
- Authors: Dmitry Vostokov, Software Diagnostics Services, Dublin School of Security
- Publisher: OpenTask (March 2024)
- Language: English
- Product Dimensions: 28.0 x 21.6
- Paperback: 341 pages
- ISBN-13: 978-1912636952

Theoretical Software Diagnostics, Fourth Edition
The following direct links can be used to order the book now:
Available in PDF format from Software Diagnostics Technology and Services
Available in PDF format from Leanpub
Available in ultra-premium color paperback format from Amazon and Barnes & Noble
Available in Kindle print replica format from Amazon
The book is also included in the following training packs and reference sets:
Pattern-Oriented Software Diagnostics and Anomaly Detection Reference Set
Complete Pattern-Oriented Software Diagnostics Training Pack
Contains reprinted articles in full color (including more than 230 figures) from 16 volumes of Memory Dump Analysis Anthology (Diagnomicon) related to pattern-oriented software diagnostics with additional comments showing the historical development of this autonomous and distinctive discipline over the last 18 years. In addition to 15 new articles, the fourth edition includes updated threads of thinking, a list of mathematical concepts, and notes’ references, and was completely remastered.
Product information:
- Title: Theoretical Software Diagnostics: Collected Articles, Fourth Edition
- Authors: Dmitry Vostokov, Software Diagnostics Institute
- Language: English
- Product Dimensions: 21.6 x 14.0
- PDF: 398 pages
- Publisher: OpenTask (February 2024)
- ISBN-13: 978-1912636914
Table of Contents
Bird's-eye View of Pages
Book: Accelerated Windows Debugging 4D, Fourth Edition
The following direct links can be used to order the book now:
Available in PDF format and optional Memory Dump Analysis Anthology from Software Diagnostics Technology and Services
Available in PDF format from Leanpub
Available in ultra-premium color paperback format from Amazon and Barnes & Noble
Available in Kindle print replica format from Amazon
The book is also included in the following training packs:
WinDbg Training Pack
Pattern-Oriented Windows Debugging Training Pack
Complete Pattern-Oriented Software Diagnostics Training Pack
The full transcript of Software Diagnostics Services training with 16 step-by-step exercises, notes, and source code of specially created modeling applications. Learn live local and remote debugging techniques in the kernel, user process, and managed .NET spaces using WinDbg debugger. The unique and innovative course teaches unified debugging patterns applied to real problems from complex software environments. The fourth edition was fully reworked and updated to use the latest WinDbg, added x64 disassembly review and Rust language to the existing and improved C/C++ and C# exercises.
Prerequisites: Working knowledge of one of these languages: C, C++, C#, Rust. Operating system internals and assembly language concepts are explained when necessary.
Audience: Software engineers, software maintenance engineers, escalation engineers, security and vulnerability researchers, malware and memory forensics analysts who want to learn live memory inspection techniques.
- Title: Accelerated Windows Debugging4: Training Course Transcript and WinDbg Practice Exercises, Fourth Edition
- Authors: Dmitry Vostokov, Software Diagnostics Services
- Publisher: OpenTask (February 2024)
- Language: English
- Product Dimensions: 28.0 x 21.6
- PDF: 372 pages
- ISBN-13: 978-1912636723

Defect Mechanism Patterns (DMP), Part 1
In 2015, we introduced patterns-based root cause analysis methodology by adding software problem mechanisms to accompany software diagnostic problems and their analysis patterns. We also planned to start populating the new pattern catalog at that time, but due to other developments and ideas, we have postponed it until now. We also plan to include a new pattern catalog and case studies in our modeling software defects course.
Usually, an identified software diagnostic problem may have several different mechanisms, and a mechanism may contribute to several diagnostic signs and symptoms. Knowing such mechanisms helps greatly in modeling a problem, devising a debugging strategy, and proposing a code fix.
We start with the Spiking Thread memory analysis pattern, which has concrete analysis pattern variants for Windows, Linux, and macOS.
From its Stack Trace, we may identify the source code location. If the code uses some memory-intensive data structure, we may have an instance of Inefficient Container Implementation. Another mechanism to consider is Partial Breaking Functionality. The defect mechanism pattern names are provisional and may change as more patterns are added that require name revisions for generality, consistency, and perhaps just better names.
Inefficient Container Implementation is when a wrong container or flawed implementation is used for memory and CPU-bound code. For example, using a contiguous vector instead of a linked list may affect CPU resource consumption on insertions and deletions. Some containers, such as queues, may use underlying container implementations that can be replaced.
Partial Breaking Functionality is when we have a potentially infinite loop with checks for some conditions that prevent it from running forever. However, the list of such conditions is only partially implemented, leaving some conditions unchecked, which causes a real infinite loop with the detected CPU consumption.
Carnot Cycle Metaphor for Trace and Log Analysis
Recently, we added a few “thermodynamic” analysis patterns to our trace and log analysis pattern catalog, such as Trace Volume, Trace Temperature, and, finally, derived from an ideal gas equation metaphor, Trace Pressure. These patterns allow us to employ a Carnot cycle metaphor for a typical analysis cycle:
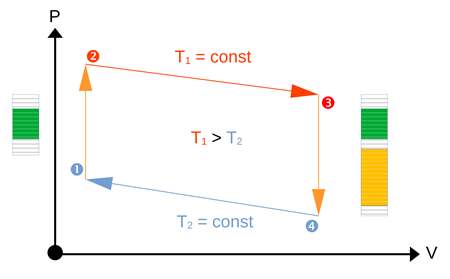
Initially, we have a low temperature (low importance) for a low volume of traces.
- During the incident, temperature (importance of traces) rises, triggering the rise in pressure.
- The volume of collected traces increases during investigations, and the pressure may go up or down.
- Once the problem is solved, the temperature comes down.
- During this phase, we do a retrospective and gradually reduce the volume of traces necessary for continuous monitoring to its original volume.
Book: Accelerated Disassembly, Reconstruction and Reversing, Third Edition
The following direct links can be used to order the book now:
Available in PDF format with the optional recording and Memory Dump Analysis Anthology from Software Diagnostics Technology and Services
Available in PDF format from Leanpub
Available in ultra-premium color paperback format from Amazon and Barnes & Noble
Available in Kindle print replica format from Amazon
The book is also included in the following training packs:
WinDbg Training Pack
Windows Memory Dump Analysis for Endpoint Security Training Pack
Pattern-Oriented Disassembling and Reversing Training Pack
Complete Pattern-Oriented Software Diagnostics Training Pack
The book contains the full transcript of Software Diagnostics Services training. Learn disassembly, execution history reconstruction, and binary reversing techniques for better software diagnostics, troubleshooting, debugging, memory forensics, vulnerability, and malware analysis on x64 Windows platforms. The course uses a unique and innovative pattern-oriented analysis approach to speed the learning curve. The training consists of practical step-by-step, hands-on exercises using WinDbg and memory dumps. More than 25 ADDR patterns are covered, and many concepts are illustrated with Memory Cell Diagrams. This training requires a working knowledge of C and C++ programming languages. Operating system internals and assembly language concepts are explained when necessary. The primary audience for this training is software technical support and escalation engineers who analyze memory dumps from complex software environments and need to go deeper in their analysis of abnormal software structure and behavior. The course is also useful for software engineers, quality assurance and software maintenance engineers who debug software running on diverse computer environments, security researchers, malware, and memory forensics analysts who have never used WinDbg to analyze computer memory. The third edition includes the x64 disassembly review and the internals of C++ virtual function calls.
- Title: Accelerated Disassembly, Reconstruction and Reversing: Training Course Transcript and WinDbg Practice Exercises with Memory Cell Diagrams, Third Edition
- Authors: Dmitry Vostokov, Software Diagnostics Services, Dublin School of Security
- Publisher: OpenTask (September 2023)
- Language: English
- Product Dimensions: 28.0 x 21.6
- PDF: 269 pages
- ISBN-13: 978-1912636679

Table of Contents and sample exercise
Slides from the training
Accelerated Linux Disassembly, Reconstruction and Reversing, Second Edition
The following direct links can be used to order the book now:
Available in PDF format with optional recording and Memory Dump Analysis Anthology from Software Diagnostics Technology and Services
Available in PDF format from Leanpub
Available in ultra-premium color paperback format from Amazon and Barnes & Noble
Available in Kindle print replica format from Amazon
The book is also included in the following training packs:
GDB Training Pack
Linux Memory Dump Analysis for Endpoint Security Training Pack
Pattern-Oriented Disassembling and Reversing Training Pack
Complete Pattern-Oriented Software Diagnostics Training Pack
The book contains the full transcript of Software Diagnostics Services training. Learn disassembly, execution history reconstruction, and binary reversing techniques for better software diagnostics, troubleshooting, debugging, memory forensics, vulnerability, and malware analysis on x64 (x86_64) and A64 (ARM64, AArch64) Linux platforms. The course uses a unique and innovative pattern language approach to speed up the learning curve. The training consists of practical step-by-step, hands-on exercises using GDB and Linux core memory dumps. Covered more than 25 ADDR patterns originally introduced for the x64 Windows platform, and many concepts are illustrated with Memory Cell Diagrams. The prerequisites for this training are a working knowledge of C and C++ programming languages. Operating system internals and assembly language concepts are explained when necessary. The primary audience for this training is software technical support and escalation engineers who analyze memory dumps from complex software environments and need to go deeper in their analysis of abnormal software structure and behavior. The course is also useful for software engineers, quality assurance, and software maintenance engineers who debug software running on diverse cloud and endpoint computer environments, SRE and DevSecOps, security and vulnerability researchers, and malware and memory forensics analysts who have never used GDB for analysis of computer memory. The book also features ADDR pattern descriptions summarized after each exercise. The second edition includes a review of relevant assembly language fundamentals and relevant differences between GCC and Clang.
- Title: Accelerated Linux Disassembly, Reconstruction and Reversing: Training Course Transcript and GDB Practice Exercises with Memory Cell Diagrams, Second Edition
- Authors: Dmitry Vostokov, Software Diagnostics Services
- Publisher: OpenTask (March 2023)
- Language: English
- Product Dimensions: 28.0 x 21.6
- PDF: 282 pages
- ISBN-13: 978-1912636747

Table of Contents and sample exercise
Slides from the training
Book: Malware Narratives, Revised Edition
The following direct links can be used to order the book now:
Available in PDF format from Leanpub
Available in ultra-premium color paperback format from Amazon and Barnes & Noble
Available in Kindle print replica format from Amazon
The book is also included in the following training packs and reference sets:
Pattern-Oriented Software Diagnostics and Anomaly Detection Reference Set
Pattern-Oriented Trace and Log Analysis Training Pack
Pattern-Oriented Malware Analysis Training Pack
Complete Pattern-Oriented Software Diagnostics Training Pack
Software Narratology, the science of software stories, found its successful application in software diagnostics of abnormal software behavior, especially in the pattern-oriented analysis of software logs from complex systems with millions of events, thousands of threads, hundreds of processes and modules. This is a revised and updated transcript of the Software Diagnostics Services seminar on the new application of software narratology to malware analysis.
- Title: Malware Narratives: An Introduction, Revised Edition
- Authors: Dmitry Vostokov, Software Diagnostics Services
- Publisher: OpenTask (October 2023)
- Language: English
- Product Dimensions: 28.0 x 21.6
- Paperback: 55 pages
- ISBN-13: 978-1912636525

Introducing Lov Language

In the past, I paid little attention to traditional performance and system behavior visualizations, for example, for time series. My own visualizations included Dia|gram graphical language for software narratives such as traces and logs and, recently, memory snapshots. My latest exposure to open-source observability and visualization tools led me to think about how to describe patterns I see in a pattern language. It is easy to communicate what I see by just sending the picture, but often, we need to compare it to the previous observations or do some symbolic processing of such information.
I decided to tailor existing rich diagnostic analysis pattern languages I developed over the last +15 years into the Language of visualizations that I simply call the Lov language, my new old love of visualizations of software behavior (no pun intended). It is not a programming language but primarily a language for description and analysis; also, it can be used for hypothesis testing and simulation with the appropriate tool support. The initial inspiration for Lov comes from two dual activities: visualization synthesis for time series data and analysis of such visualizations. For a simple initial illustration, the visualization description above of CPU consumption for all processes in the system reuses the existing Discontinuity for all PID Adjoint Threads of Activity and Blackout trace and log analysis patterns. We also see Signals for Counter Values. More Lov to come in the forthcoming months.